Sistemas de recomendaciones basados en contenido
Existen diversos métodos y estrategias utilizados a la hora de crear sistemas de recomendaciones, estos buscan hacer recomendaciones de ítems a usuarios ya sea con el fin de que interactúen con ellos, se trate de un video, una canción, una película, un producto etc. En este blog explicare varias formas en que se puede construir un sistema que recomiende dichos ítems a los usuarios, hablaré un poco del panorama general pero me centraré más en explicar aquellos sistemas que toman en cuenta las características de los items para hacer la recomendación.
¿Qué es un sistema de recomendaciones?
Podríamos definir un sistema de recomendaciones como aquel que se encarga de hacerle sugerencias a los usuarios acerca de con que items del sistema interactuar, estos ítems pueden ser cualquier cosa, un vídeo, un blog, un post, un producto, etc.
La forma más fácil de recomendar algo a un usuario es simplemente recomendado lo más popular, pero claro aquí estamos ignorando cualquier variable salvo que tan popular es un ítem, por lo tanto estamos recomendando lo mismo a todos los usuarios, esto puede funcionar en ciertas ocasiones, como cuando no tenemos muy poca información de un usuario, pero no es lo ideal, ya que cada quien tiene gustos diferentes y lo que es una buena recomendación para una persona puede no serlo para otra.
Es en esos casos donde entran los algoritmos de aprendizaje, que nos permiten tomar datos datos de nuestros usuarios y los ítems del sistema y hacer recomendaciones más personalizadas para cada quien.
Existe una gran variedad de metodos para hacer recomendaciones, en este blog no hablaremos mucho de ellos pero sí un poco de cada uno, ya que en particular profundizaremos en los basados en contenido, si quieres saber más sobre el panorama general para crear sistemas de recomendación este es un gran post para ello: Introduction to recommender systems
Tipos de sistemas de recomendación
Existen dos formas principales de crear un sistema de recomendaciones, una es usando el contenido de los ítems y la otra es a base de filtros colaborativos, se dará una breve explicación de la segunda para después profundizar en la primera.
Filtros colaborativos.

en estos filtros tú no utilizas información acerca de los ítems del sistema o de los usuarios, más allá de sus interacciones, aquí se modelan dichas interacciones como una matriz, donde los renglones representan usuarios y las columnas ítems, y cada entrada es una interacción, las cuales pueden ser un megusta o no me gusta, una simple bandera, una calificación, el número de estrellas, el tiempo de interacción, etc. el objetivo es predecir los valores faltantes de la matriz y tomar esas predicciones para escoger ítems adecuados para cada usuario.
Si tenemos una página donde se pueden leer artículos, y se puede calificar un artículo del uno al diez sería razonable pensar que los mejor es recomendarle al usuario aquellos artículos a los cuales el mismo usuario vaya ponerles una calificación alta, de modo que el primer paso para hacer la recomendación es estimar la calificación que tendrá cada artículo y luego ordenarlos para sugerirle al usuario que vea los que tengan la calificación más alta.
Si nuestra interacción es un valor booleano, le gusto o no le gusto, entonces quizá lo mejor sea recomendarle aquellos con mayor probabilidad de que le gusten, o tomar una muestra aleatoria de todos los que sea probable que le gusten.
Para hacer la predicción de cuánto valdrá la interacción existen dos maneras, una es haciendo búsquedas y la otra es utilizando un modelo. Las búsquedas se pueden realizar ya sea buscando usuarios parecidos a nuestro usuario y recomendando items que les haya gustado a esos usuarios, o buscando items similares a los que le gustaron al usuario.
Si se buscan usuarios similares esto se hace usando las interacciones con otros ítems, si dos personas tienen muchos gustos en común, y a una le gusta algo, probablemente a la otra también le guste esto. Partiendo de esta idea se puede usar alguna métrica sobre los vectores renglones de la matriz de interacciones que representan a los usuarios y buscar a los usuarios más cercanos, luego simplemente recomendamos aquellos ítems que hayan sido popular entre los usuarios cercanos.
En el caso de buscar ítems parecidos a los que le gustaron a un usuario, se hace lo mismo pero con los vectores columna de la matriz, es decir dos items se parecen mas cuantos mas usuarios en comun tengan.
Ambas formas tienen sus ventajas y desventajas, por ejemplo que buscar usuarios similares es un método que genera resultados más personalizados, pero también es más sensible cuando hay pocos datos, en cambio buscar items similares genera resultados más personalizados ya que cada ítem está formado por las interacciones múltiples usuarios, que posiblemente no se parecen mucho entre sí.
Una mejor forma de rellenar los valores faltantes de la matriz sin tener que guardar toda la información de las interacciones es buscar una forma de representar dicha matriz, para lo cual se puede hacer una variante de la descomposición en valores singulares (SVD) generando dos matrices cuyo producto nos da la matriz de interacciones, una de estas matrices representa la información de los usuarios y la otra de los ítems, si la matriz de interacciones tiene dimensiones n x m, estas dos nuevas matrices tienen dimensiones n x h y h x m, donde n es el número de usuarios, m el número de ítems y h el número de características de cada representación. Entonces una matriz está asociada a los usuarios y a los ítems.
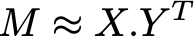
Para encontrar estas dos matrices se pueden escoger dos matrices con valores aleatorios y luego optimizar para que su producto sea igual a los valores conocidos de la matriz de interacciones.
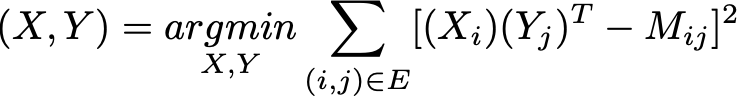
en cada iteración se puede fijar el valor de una matriz y optimizar respecto a la otra. Hay que tomar en cuenta que Xi y Yj podrían ser salidas de un regresor binario o softmax, incluso una red neuronal, dependiendo de que tipo de valores tenga la matriz M.
Sistema basado en contenido
En estos se toman las características conocidas de los ítems para recomendar ítems similares a los ítems con los que el usuario ya interactúa, otra alternativa es crear un modelo para predecir dichos ítems. Las características pueden ser palabras claves o tags que se hayan asignado, un texto que funcione de descripción, un género, entre otras cosas. Se modifican las características en vector para poder usar alguna métrica entre vectores y encontrar vectores similares.
Cuando se decide usar un modelo este puede predecir a qué tipos de usuario le gustara un ítem o que tipos de items le gustaran a un usuario, si decidimos hacer un predictor para cada usuario que recomiende items dadas sus características entonces tendremos tantos predictores como usuarios, si por el contrario queremos que cada ítem tenga un predictor que diga a cuales posibles usuarios sería bueno recomendarlo, entonces tendremos un predictor por ítem.
El predictor que se escoja depende del tipo de las interacciones, si lo que quieres es saber si a un usuario le gustara un producto entonces lo indicado es hacer una regresión logística, si se quiere predecir el valor de una calificación se tendría que hacer una regresión lineal, incluso se puede usar una red neuronal con el tipo de salida requerido.
Supongamos que decidimos hacer un sistema de recomendaciones basado en contenido para una pagina que vende celulares, las características podrían ser la marca del celular, el modelo, el año de lanzamiento, las especificaciones técnicas y demás, si nosotros tenemos un regresor lineal para estimar el número de estrellas que un usuario le da a un celular, tendríamos una matriz X de n x v, donde n es el número de usuarios y v es la dimensión del vector de características, nuestros datos serian una matriz Y de v x m donde m es el número de ítems, y el problema de regresión se podría resolver a
Que es la misma fórmula que teníamos en los filtros colaborativos solo que esta vez Y es una matriz que no cambia, se podría ver como nuestras entradas, y X es la matriz de pesos que queremos ajustar para aquellos valores de M que conocemos. En este caso Xi también puede ser la salida de una red neuronal, osea que para cada usuario el predictor sería una red neuronal.
Algunas consideraciones
Tantos los sistemas basados en contenido como los filtros colaborativos sufren del problema del arranque frío (Cold Start Problem), el cual se presenta cuando un usuario o ítem nuevo entra en el sistema, en los sistemas basados en contenido sólo se presenta si se trata de un usuario, ya que no hay información para hacer predicciones, esto puede perdurar incluso después de que se hayan generado datos ya que la cantidad de datos existentes e muy poca.
Incluso cuando los sistemas basados en contenido sufren menos de este problema ya toman en consideración las características de los ítems y/o los usuarios para hacer la recomendación se pueden ver afectados de cierta manera si lo que se quiere es aprender que items son los favoritos de un usuario.
Para evitar el arranque frío se puede usar características del usuario, como región, idioma, edad y otras variables para recomendarle items que sean populares para usuarios similares, o simplemente recomendarle los ítems más populares del sistema. Para el caso de los ítems se puede usar características del ítem para que sea recomendado a usuarios a los que les gusto algun item similar en lo que se recolecta datos, o recomendarlo aleatoriamente, aunque esto último no sea tan recomendado. Es justo lo anterior lo que define a los sistemas híbridos, sistemas que combinan lo mejor de los sistemas basados en contenido y los filtros colaborativos, ya sea iniciando con uno cuando hay pocos datos y luego cambiando o promediando los valores de salida, también se puede asignar un peso a cada parte del sistema de modo que se determine cuánta decisión tienen en la recomendación final.
Pequeña implementación de un sistema basado en contenido
En esta libreta: https://github.com/ricardoamata/Proyecto-ML/blob/master/Sistema_recomendador_basado_en_contenido.ipynb puedes encontrar una implementación de un sistema basado en contenido para recomendar películas utilizando dos datasets uno es Wikipedia Movie Plots, el cual contiene textos que describen la trama de las películas, el otro es Movie Lens que contiene datos de más de 100 mil usuarios que han calificado más de 25 mil películas con un número del uno al cinco.
En la libreta lo que se hace es limpiar los textos y luego codificarlos usando el Universal Sentence Encoder, una red neuronal entrenada para codificar textos en vectores densos de 512 tal que textos similares tengan vectores con distancias más cortas a textos que no se parecen. Luego se seleccionaron aquellas películas que estaban en ambos datasets y se procedió a entrenar un regresor lineal para predecir las calificaciones puestas por los usuarios que tienen las películas. El error de entrenamiento fue de 5.2074 y el error de prueba fue de 5.25, bastante cercanos, por lo que creo que con una red neuronal sería posible alcanzar mejores resultados.
algunos ejemplos de predicciones de calificaciones hechas por una muestra aleatoria de usuarios:
| Real | Predicción | Titulo |
|---|---|---|
| 4.5 | 3.699524 | Run All Night |
| 1.5 | 2.195683 | Saving Private Ryan |
| 4.0 | 1.683317 | Dr. Strangelove or: How I Learned to Stop Worr… |
| 4.0 | 1.487666 | Die Hard |
| 2.5 | 1.292135 | Shrek |
| 4.0 | 3.703663 | Shine |
| 2.0 | 2.336115 | Six Days Seven Nights |
| 4.0 | 3.052016 | Top Gun |
| 5.0 | 3.368618 | Time Bandits |
| 4.0 | 2.062055 | Office Space |
| 3.5 | 1.556051 | October Sky |
| 2.5 | 2.838505 | Addams Family Values |
| 3.0 | 2.404784 | Tropic Thunder |
| 1.5 | 1.106677 | Sex, Lies, and Videotape |
| 2.0 | 2.427603 | Empire Records |
| 3.0 | 3.856894 | For the Love of Benji |
| 2.5 | 2.956768 | Jumanji |
| 2.0 | 3.212133 | Brazil |
| 3.0 | 2.692718 | Bounce |
| 4.5 | 2.558084 | Dredd |
| 2.0 | 2.132428 | Butch Cassidy and the Sundance Kid |
| 4.0 | 1.840417 | Little Miss Sunshine |
| 4.0 | 2.521581 | Apollo 13 |
| 4.0 | 2.721938 | Ghost in the Shell |
| 3.0 | 2.438640 | Eragon |
se seleccionó un usuario aleatorio y se le recomendó un lista de películas basadas en sus calificaciones:
Películas que le gustaron al usuario 103627:
“Stargate”
“Century”
“Honey, I Blew Up the Kid”
“Milk Money”
“Backbeat”, “Homage”
“Peanuts - Die Bank zahlt alles”
“Convent, The (O Convento)”
“Crows and Sparrows (Wuya yu maque)”
“All Over Me”
“You Can’t Take It with You”
“Devil and Max Devlin, The”
“Permanent Midnight”
“Kindred, The”
Películas recomendadas
“Coneheads”, “Heavy Metal”
“Some Girls Do”
“Outland”
“Cypher”
“Teenagers from Outer Space”
“Snowpiercer”
“Freejack”
“Escape from Planet Earth”
“Hostage”
Conclusiones
Con la gran variedad de sistemas de recomendación que hay se puede encontrar uno que se adapte a las necesidades de cualquier problema, y se pueden combinar para resolver problemas que presentan estos individualmente.